|
What If We Knew About RL on Chain-of-Thought in the GPT-2 Era? June 29, 2026 Experiments done with assistance mostly from Codex (GPT-5.5). Blog post written with assistance from Claude Opus 4.8 based on the tweet thread (tweet thread mostly written by myself). |
|
A question I've been pondering: what if we'd known about o1-style RL on chain-of-thought back in the early days of LLMs? As a fun side project, I took the GPT-2 1.5B weights and ran a basic SFT + RL pipeline on GSM8K. It turns out that this almost matches the performance of a fine-tuned 12B GPT-3 on GSM8K — a model trained with more than 100× the pre-training compute. Additionally, the GPT-3 models from the GSM8K paper were allowed usage of an external calculator. No such affordances were given to the GPT-2 model, making the result even cooler! 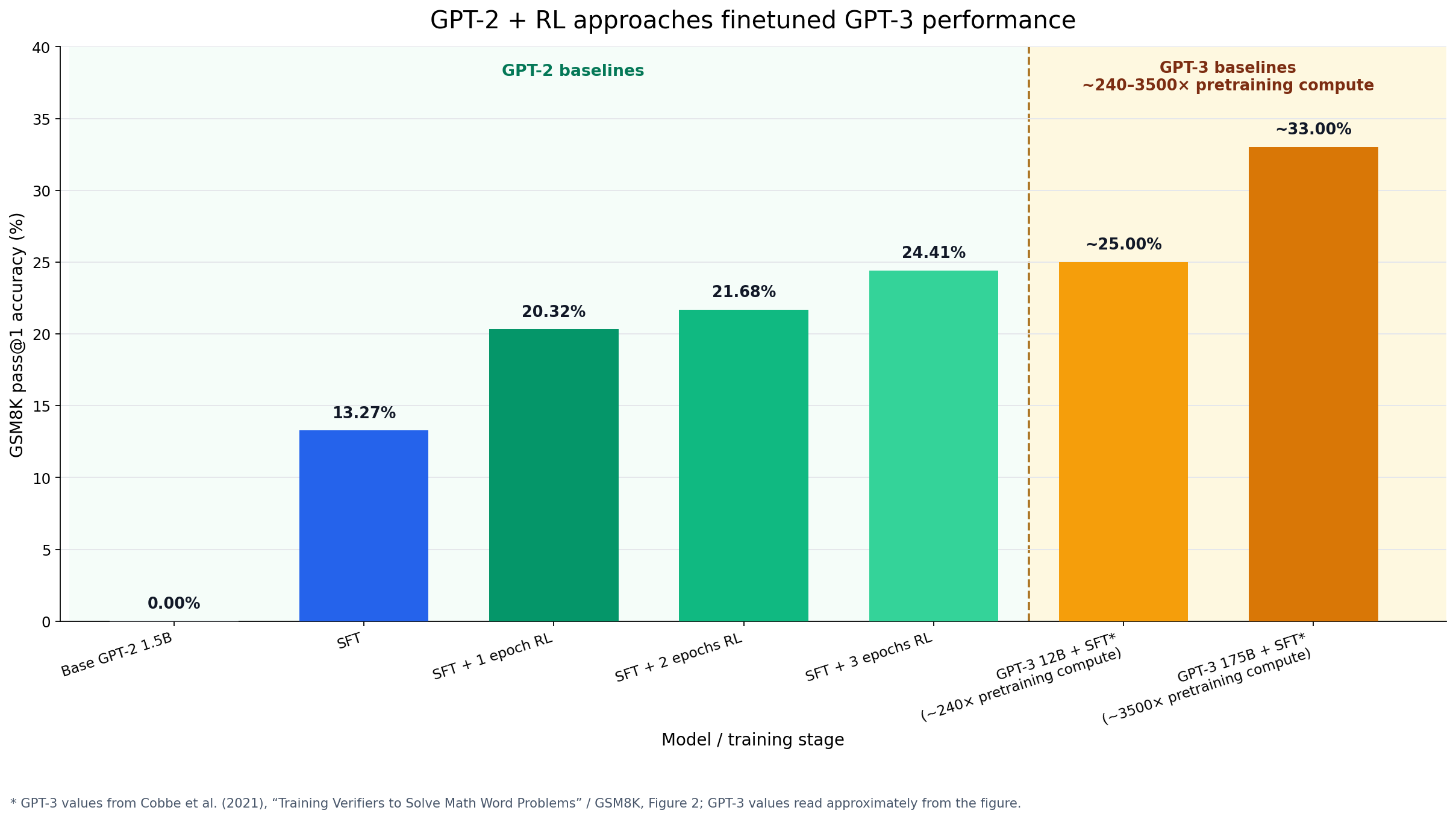
GPT-2 + SFT + RL lands just shy of a fine-tuned 12B GPT-3; the GPT-3 baselines shown used >100× (up to ~3500×) more pre-training compute. GPT-3 numbers read approximately from Cobbe et al. (2021). GPT-3 was allowed usage of a calculator, GPT-2 had no access to external tooling. In effect, the question asks how much of recent progress in AI is due to pure scaling versus scaling plus algorithmic advances. Imagine you time travel back to 2019 with today's knowledge. You don't have access to modern data, compute, or models. What could you actually do? SummaryI generated around $100 worth of SFT data from GPT-5.4 mini (with a few harder problems done by GPT-5.5) on around 2000 problems from the GSM8K train set. The remaining 5,473 problems were reserved for RL. I then did SFT + RL (GRPO) for 3 epochs using around $100 worth of compute on A100s. Accuracy was measured at temperature 0 on the held-out test set. GPT-2 + around $200 worth of data and compute ended up matching the performance of a small GPT-3 model trained on >100× as much pre-training compute. BackgroundStepping back: in 2019, the best LLM was GPT-2. It was an insane advance for its time — more important than almost anyone (myself included) expected. But compared to modern LLMs, it has a few major drawbacks. It's roughly 1000× smaller than today's frontier models (DeepSeek V4 is 1.6T params, and some closed-source models are rumored to be larger still); it's undertrained, with a token-to-parameter ratio around 6–7 versus Chinchilla's 20 (Chinchilla wasn't published until 3 years later in 2022); it was trained on lower-quality data (Reddit outlinks rather than a broad web scrape); and it has a context window of only 1024 tokens, which makes long chains of thought — or even many few-shot examples — impossible. To give a rough sense of the compute differential, GPT-2 1.5B was trained on WebText, a dataset of about 40GB of text scraped from Reddit outlinks. The size in tokens isn't reported directly, so we have to estimate it. Converting raw bytes to tokens depends on the tokenizer and the language, but for English a byte-to-token ratio of roughly 4:1 is a reasonable rule of thumb (each BPE token averages around 4 characters). That puts WebText at roughly 10B tokens — only about 6–7 tokens per parameter, well under Chinchilla-optimal. GPT-3 175B, by contrast, was trained on 300B tokens. Combining the ~115× parameter difference with ~30× more data, GPT-3 175B saw on the order of 3500× the FLOPs of GPT-2. The model that actually matters for this post is smaller, though: the original GSM8K paper reports results for a 12B GPT-3. GPT-3 12B was also trained on 300B tokens (assuming it's the same model referenced in the GPT-3 paper). This would make it ~240× the FLOPs of GPT-2 (~8× params, ~30× data) — and that's before accounting for the higher quality of GPT-3's web scrape versus GPT-2's Reddit outlinks. All of these FLOPs estimates also assume a single epoch over the pre-training tokens (each token seen roughly once, so FLOPs scale as ~6·params·tokens). I could not find confirmation that this was true for GPT-2, so take all estimates with a grain of salt. So GPT-2 is not a good "pretrain" by modern standards. And yet, if you know even a rudimentary version of what we now know about RL, you can nearly match the performance of models pre-trained with significantly more compute. The SFT PhaseBecause of GPT-2's small context window, I could fit at most 4 few-shot examples into the prompt. Even with those, the acceptance rate for the base model was basically 0 — meaning the model would learn nothing from RL, since every rollout was wrong. To fix this, I started with a brief SFT phase: GPT-5.4 mini wrote solutions for 2000 GSM8K problems (a few too-hard problems fell back to GPT-5.5). This cost less than $100 in 2026 dollars. 
An example SFT solution generated by GPT-5.4 mini, ending in the GSM8K answer delimiter. One important caveat. In 2019, the natural way to do SFT would have been to hire humans to write solutions by hand — tedious and expensive — so I shortcut that by having GPT-5.4 mini write them instead. The assumption is that the two would produce similar results. One could instead argue the gains come from distillation out of a stronger model. I don't believe that's the main effect: the point of SFT here is just to get the solve rate off zero so RL has something to reinforce. But I can't completely rule the distillation story out. A Tokenization BugAfter looking through a few generations, I found that GPT-2 didn't tokenize digits the way you'd want. Concretely, "200" wasn't tokenized as "2" "0" "0" — it became its own single token. This makes arithmetic very hard to learn. The fix was simple, and since we needed an SFT phase anyway, nearly free: I added spacing around digits and other mathematical symbols the model was likely to encounter. No code changes — just a change to the data. 
The same solution with spaces added around digits and math symbols, so GPT-2 tokenizes numbers digit-by-digit. The payoff: after SFT but before the tokenization fix, the model gets 11.68% on GSM8K. Fixing tokenization alone bumps that to 13.27% — an over-10% relative gain, for free. 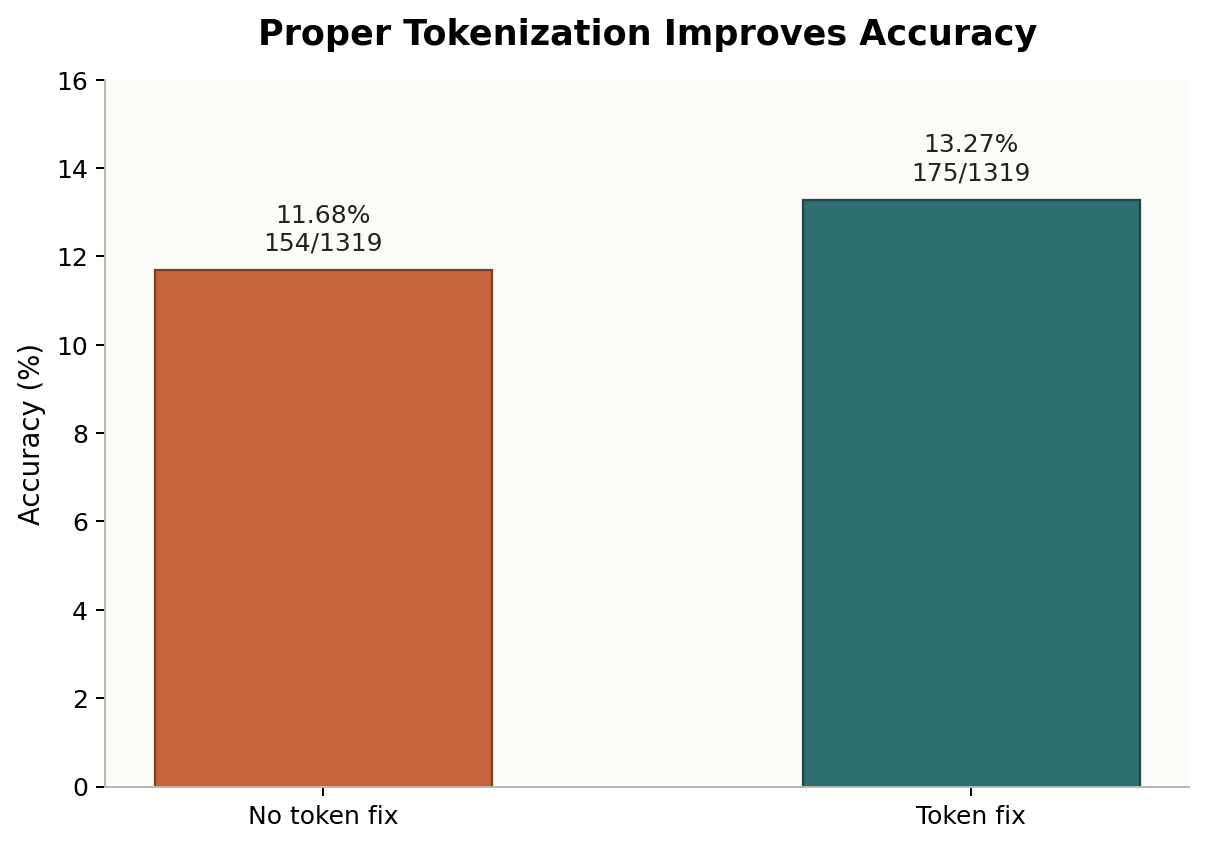
Accuracy on the full GSM8K test set, with and without the tokenization fix. The RL PhaseOn the RL side I kept it simple: basic GRPO, data batch size 1, group size 128, fully on-policy. After one epoch, accuracy climbs to 20%. After three, it's over 24% — roughly matching the 12B GPT-3 from the original GSM8K paper. 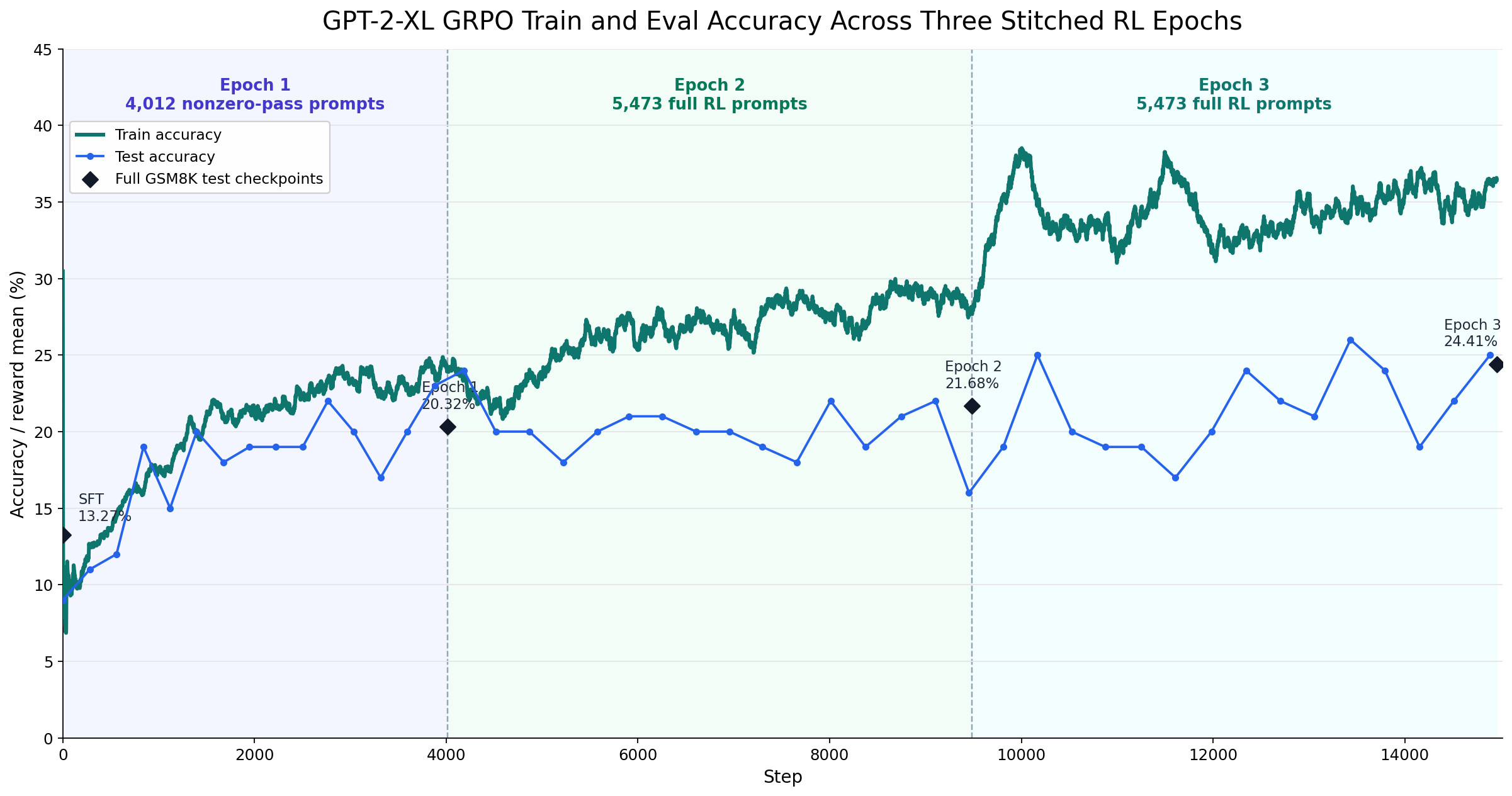
GPT-2-XL train and test accuracy across three stitched GRPO epochs. Test accuracy climbs from 13.27% (SFT) to 24.41% after three epochs. I ran everything mostly on interruptible A100 instances. The final SFT + RL run took a few days on a single A100 — under $100 at today's prices. Including all the ablations and false starts, total spend was still under $1000. Recall from the background that the 12B GPT-3 was trained with more than 100× the FLOPs of GPT-2. So RLVR on GSM8K buys you a boost roughly equivalent to pre-training a model with two orders of magnitude more compute. AblationsI tried a handful of other things, but nothing beat the obvious move (surprise, surprise): just running RL for longer. Since I only had the GSM8K problems, I capped it at 3 epochs; further epochs mostly plateaued. One caveat on the multi-epoch numbers: due to a mix of experimentation and bad planning, the three epochs were actually run as three separate runs with the optimizer state reset between each (I hadn't saved it). So each epoch starts cold rather than continuing from a warm optimizer. It's plausible this slightly underestimates what a "proper" continuous multi-epoch run would achieve. How Much Does Pretraining Matter?One ablation is testing how much pretraining matters at all. As you would expect, it matters a lot. If you initialize the GPT-2 1.5B model with random weights and run the same SFT recipe, you get only about 2% accuracy after SFT, compared to 13.5% accuracy (the pretrained model score) on a 200-question sample from the GSM8K test set. This suggests that pre-training is doing real work: even though GPT-2 is small, undertrained, and bad at arithmetic by modern standards, its language and reasoning priors are what make the SFT (and subsequent RL) stages effective. Test Time ComputeAnother question is how well this model can use test-time compute. The answer is, unfortunately, not that well. But it can use some! If you take the majority vote over samples at temperature 1 instead of the greedy answer at temperature 0, accuracy rises from 24.41% to 27.52% with vote@16. There should still be some room to grow. For that checkpoint, pass@16 is 50.87%. In other words, the majority of problems have at least one correct answer among 16 samples. The model just needs a way to find it. The original GSM8K paper had additional experiments using verifiers to improve on the initial finetuning results. I didn't have a chance to explore too much with GPT-2, but I suspect the numbers can also be improved if further exploration was done on this topic. GSM1K GeneralizationAnother fun ablation was checking whether RL on GSM8K generalized to GSM1K, a previous paper of mine which "cloned" GSM8K to check whether people were overfitting to the GSM8K benchmark. The answer is… sort of. I did not run GSM1K on the final three-epoch headline checkpoint, so the table below uses the two earlier checkpoints for which I have matching GSM8K and GSM1K vote@16 evaluations.
GPT-2 is a relatively small model. If you RL only on GSM8K, you will learn both math reasoning and a bit of whatever quirks are in the GSM8K dataset. The matched-checkpoint comparison suggests that it generalizes, but not perfectly, to GSM1K math problems, which are close to GSM8K but not perfectly in distribution. My guess is that some of the smaller model / actual distillation attempts from frontier models did not do enough RL on a general distribution of problems and ended up accidentally overfitting on the set of problems they trained on. Of course, as the master says: "the models, they just want to learn." And so the models will learn. But they will also learn to overfit if that's what you teach them. And that's (in small part) what is happening here too. GPT-2 Family Size SweepI also ran the SFT recipe across the GPT-2 family. These are SFT-only numbers on a 200-problem sample of the GSM8K test set, so they should not be compared directly to the full-test RL result. Still, they give a useful sense of how much the recipe depends on base-model size.
So model size is very important (as you would expect). A smaller GPT-2 model leaves a lot of gains on the table. And so it's likely that GPT-2-XL itself at only 1.5B params is also leaving a lot of gains on the table. Learning-Rate SweepThe SFT stage was also fairly sensitive to learning rate. In the GPT-2-XL sweep, low learning rates learned the format but did not get much GSM8K accuracy; the useful region was around 1e-5 to 2e-5. I ended up using 2e-5 as the learning rate for both SFT and RL on the basis of this and related sweeps.
In the smaller-family sweep, the best learning rate also shifted with model size: smaller models wanted higher learning rates, while GPT-2 Large and GPT-2-XL peaked lower. Training loss alone was not enough to pick the best checkpoint; for example, GPT-2 Large had a lower final training loss at 4e-5 than at 2e-5, but the 2e-5 checkpoint did better on the test sample. A Note on the Bitter LessonIt's common — especially on Twitter — to invoke the bitter lesson to argue that whoever owns the FLOPs obviously wins. I think that's a misreading. The bitter lesson says that what matters is finding the right thing to scale up. It does not say that scaling up the wrong recipe will always beat a slightly-less-scaled but more correct one. Put precisely: FLOPs are necessary but not sufficient. There are plenty of examples of organizations that held large compute leads and still failed to train good models — because they scaled the wrong recipe. ClosingI quite enjoyed doing this while funemployed. The overarching lesson, for me, is that algorithmic advances — if you can find them — are a very, very real thing. And as fast as AI progress is now, there's a real chance things go even faster soon. In a time like this, where progress is moving so fast, I thought it quite important to sit back and reflect on what I would like to do with the time that I have been given. And I have enjoyed my time reflecting. As fun as this is, I think I will do something slightly different next. And I'm very excited about it. Hugging Face Model LinksThe finetuned checkpoints are stored as named folders inside the linked Hugging Face repositories. References
CitationIf you'd like to cite this post: @misc{zhang2026rlgpt2,
author = {Hugh Zhang},
title = {What If We Knew About RL on Chain-of-Thought in the GPT-2 Era?},
year = {2026},
howpublished = {\url{https://hughbzhang.com/blog/rl-on-cot-gpt2-era.html}}
}
|