|
I recently decided to take a leave of absence from Harvard to join Scale AI and kickstart our open source AI research efforts.
|

|
|
My current work focuses on evals, test-time compute, and post-training for LLMs. Previously, I also worked on multi-agent reinforcement learning and game theory. * denotes equal or alphabetical ordering. |
|
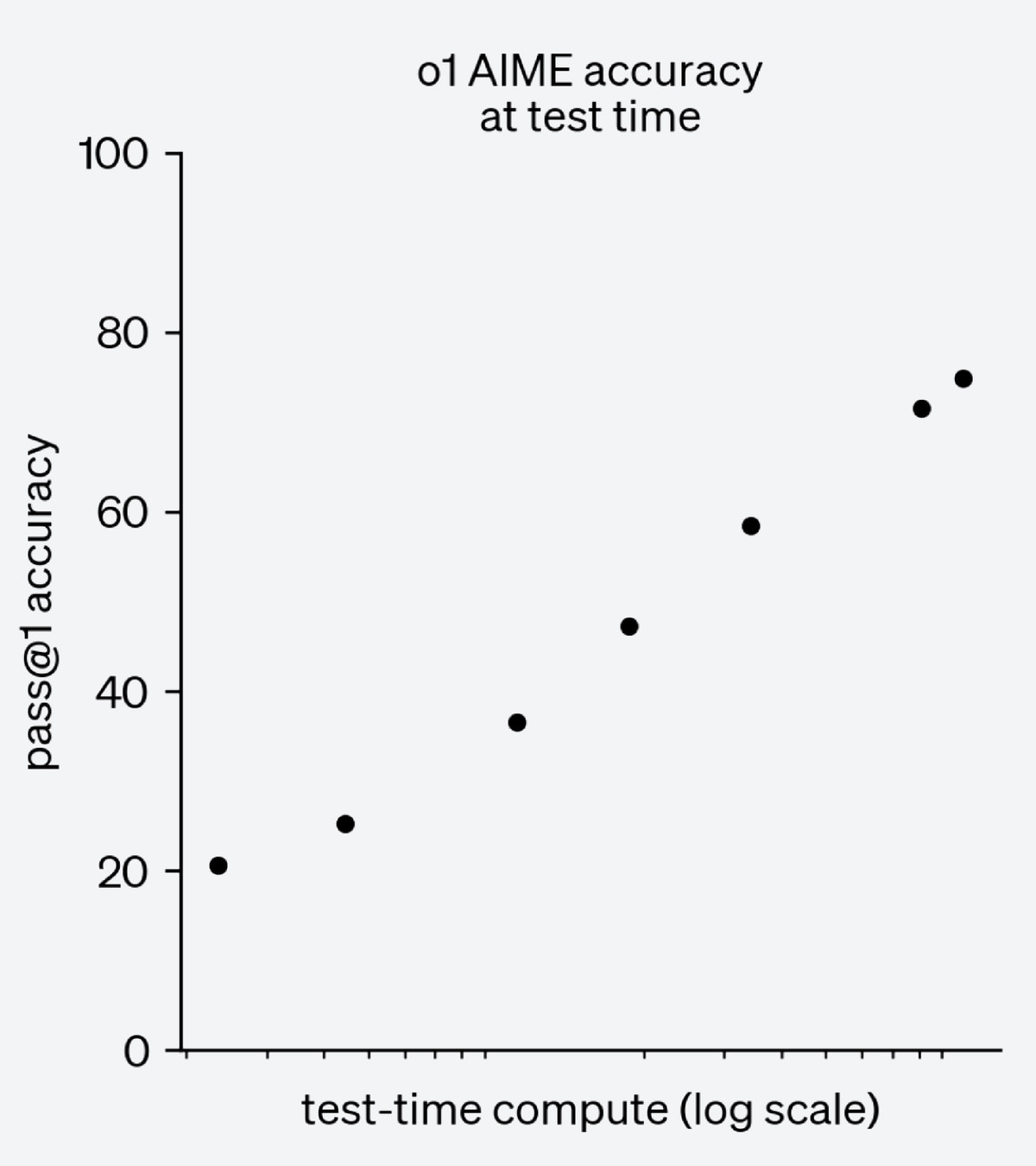
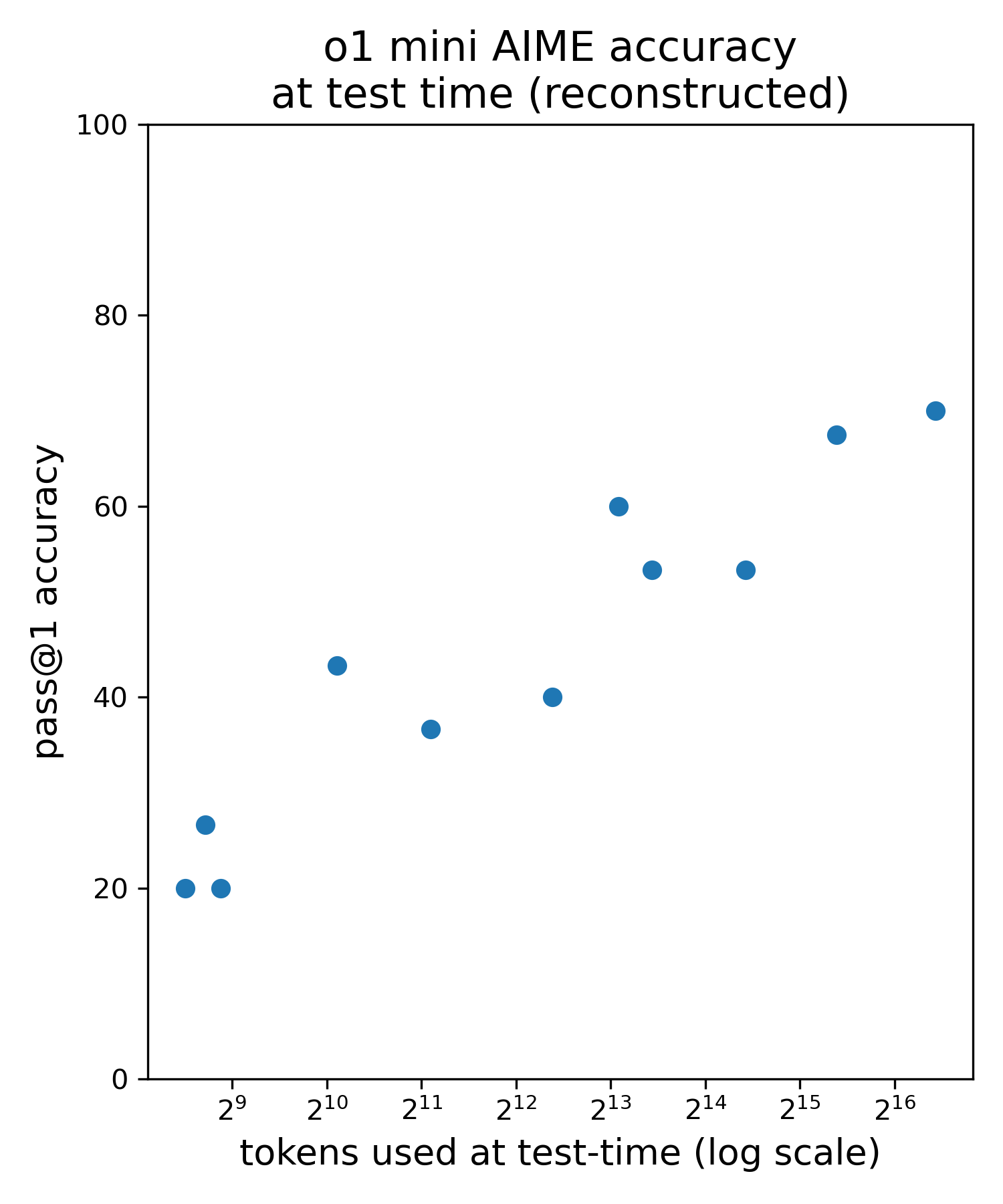
Hugh Zhang, Celia Chen Reconstructed o1 test-time scaling laws using public API access to o1-mini. |
|
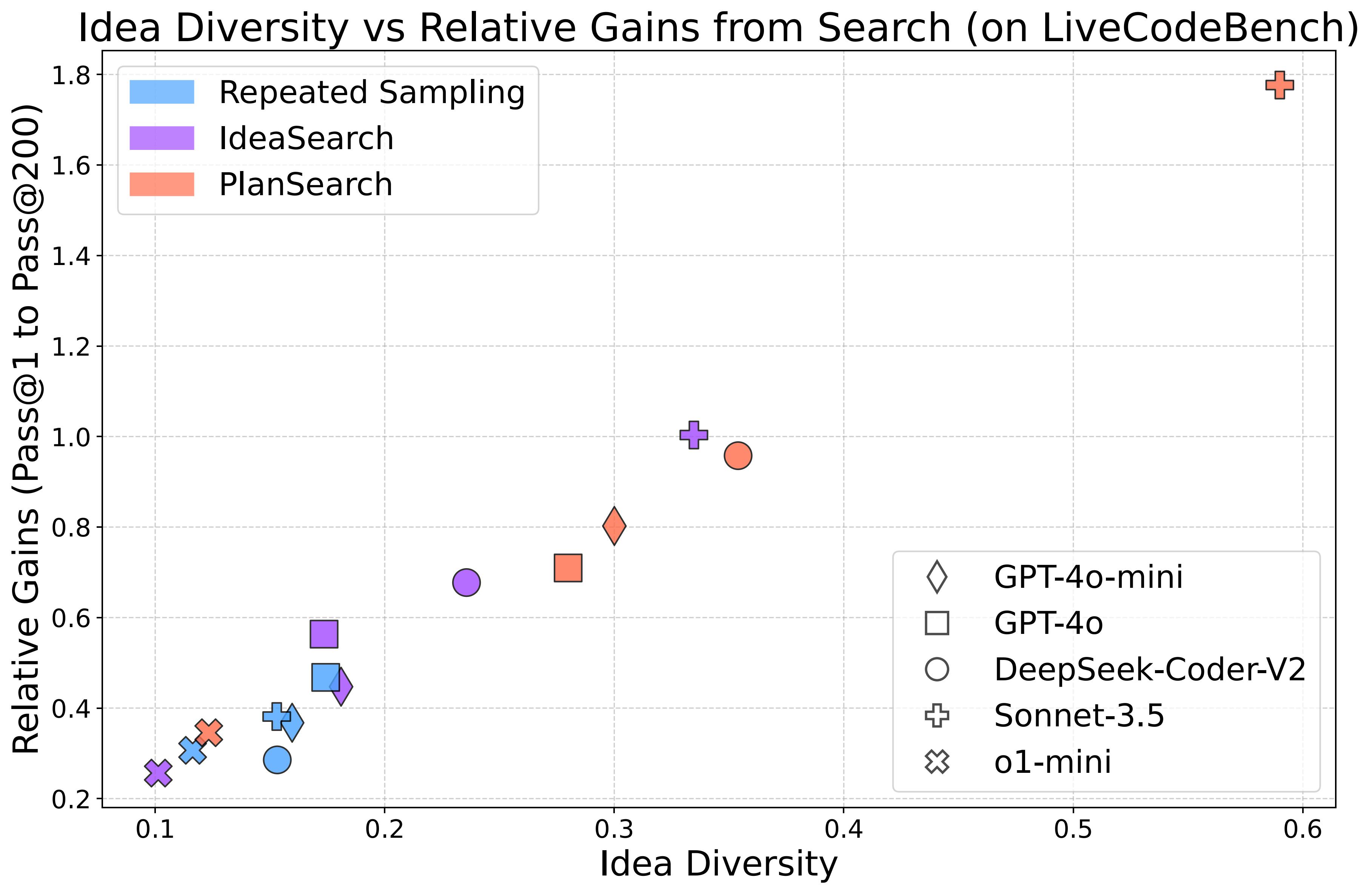
Evan Wang, Federico Cassano, Catherine Wu, Yunfeng Bai, Will Song, Vaskar Nath, Ziwen Han, Sean Hendryx, Summer Yue, Hugh Zhang twitter / twitter2 Searching over a diverse set of ideas/plans in natural language significantly helps code generation and is far more effective that repeated sampling. |
|
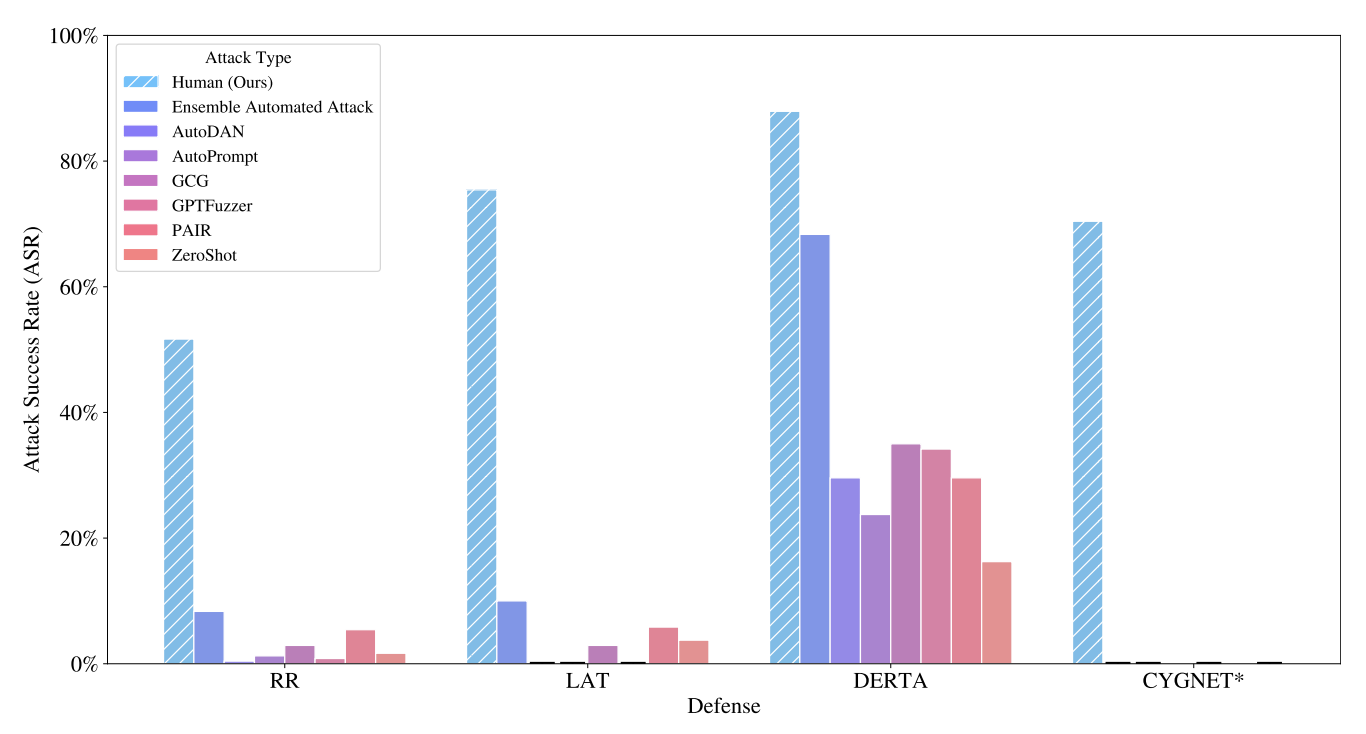
Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, Summer Yue Red Teaming GenAI Workshop @ NeurIPS, 2024 We demonstrate that multi-turn human jailbreaks can achieve >70% success rates against LLM defenses that report single-digit success rates for automated single-turn attacks. |
|
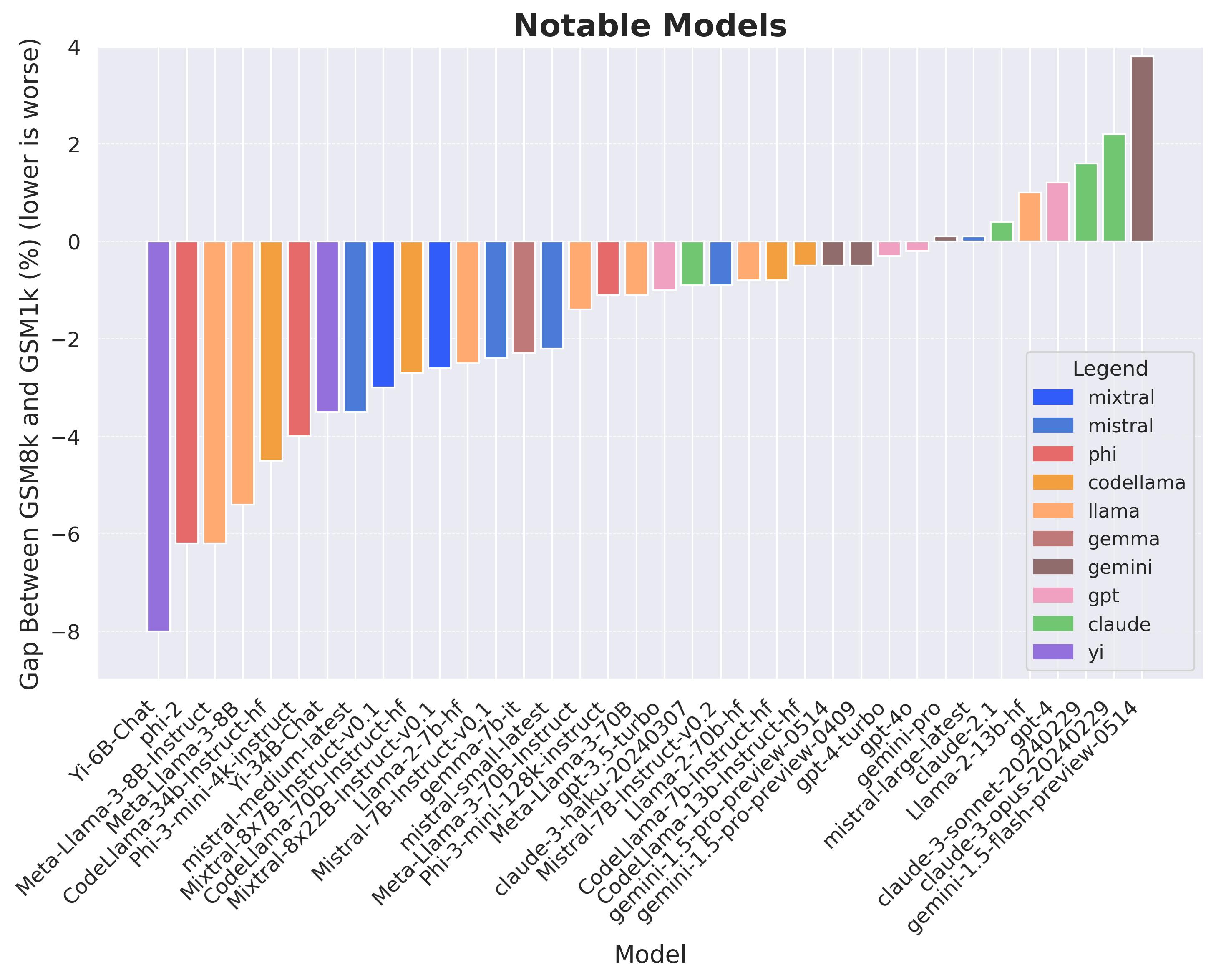
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, Summer Yue NeurIPS Spotlight (Datasets and Benchmarks Track), 2023 talk / slides / twitter / twitter2 / twitter3 / twitter4 We clone GSM8k to measure dataset contamination. Some models show signs of overfitting, but frontier models show strong generalization. |
|
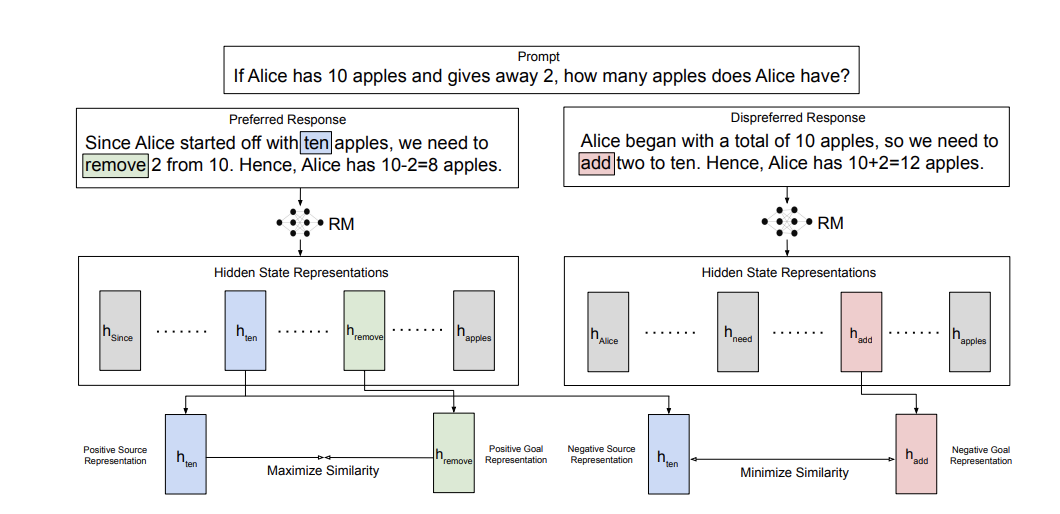
Vaskar Nath, Dylan Slack, Jeff Da, Yuntao Ma, Hugh Zhang, Spencer Whitehead, Sean Hendryx NeurIPS, 2024 Representation learning may be useful for post-training LLMs. |
|
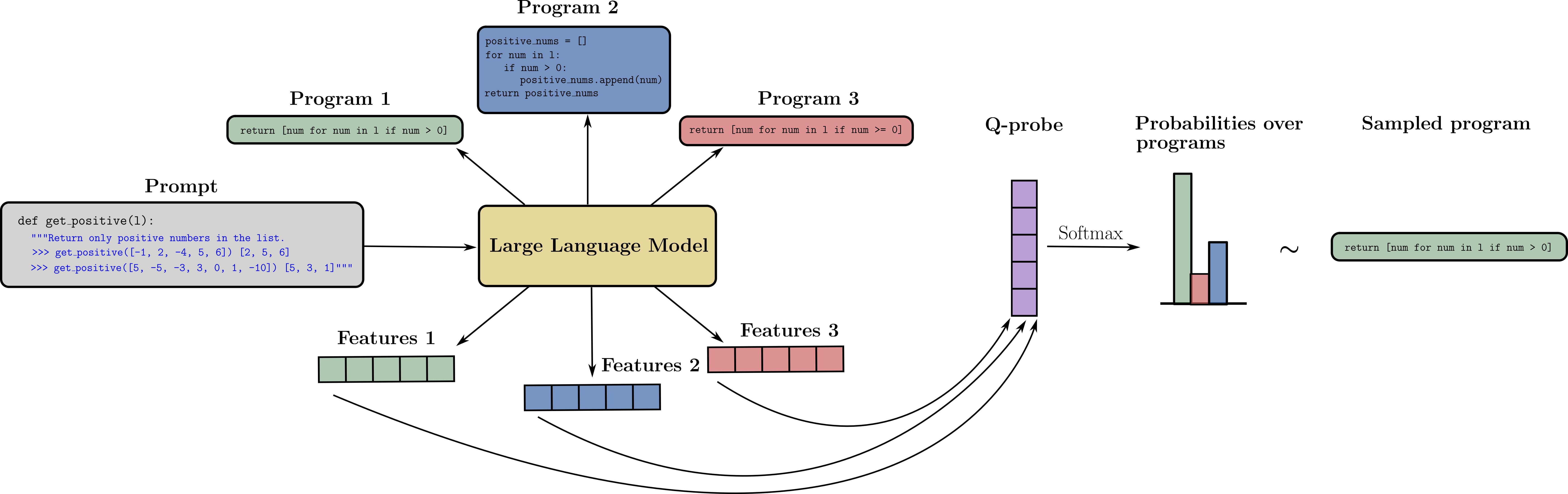
Kenneth Li, Samy Jelassi, Hugh Zhang, Sham Kakade, Martin Wattenberg, David Brandfonbrener A lightweight alternative to fine-tuning that performs better than LORA for very small datasets and requires minimal model access. |
|
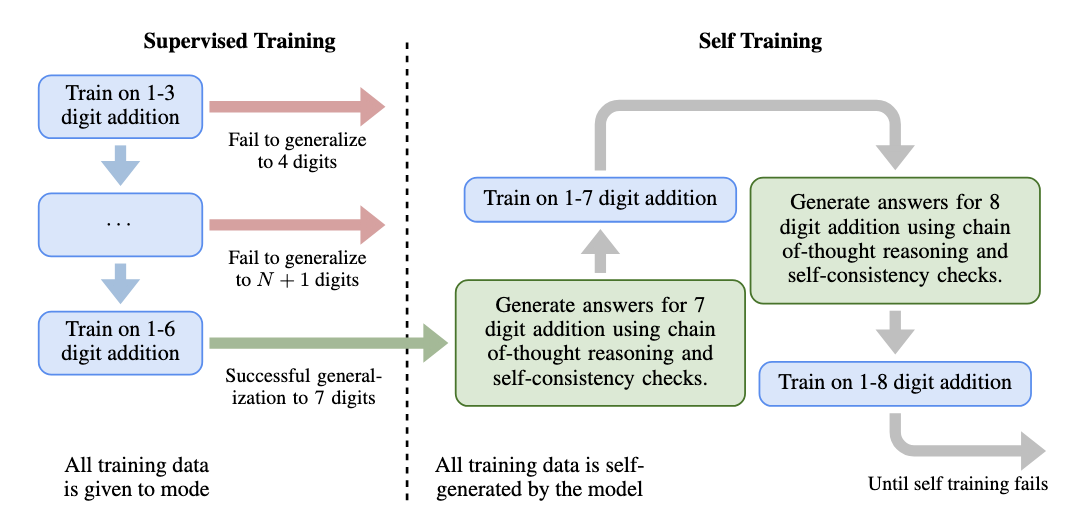
Hugh Zhang, David C. Parkes Workshop on Instruction Tuning and Instruction Following at NeurIPS 2023 twitter / slides / poster Training on chain-of-thoughts that lead to a correct answer can help a LLM self-improve and generalize far beyond their original capabilities in the toy environment of addition. |
|
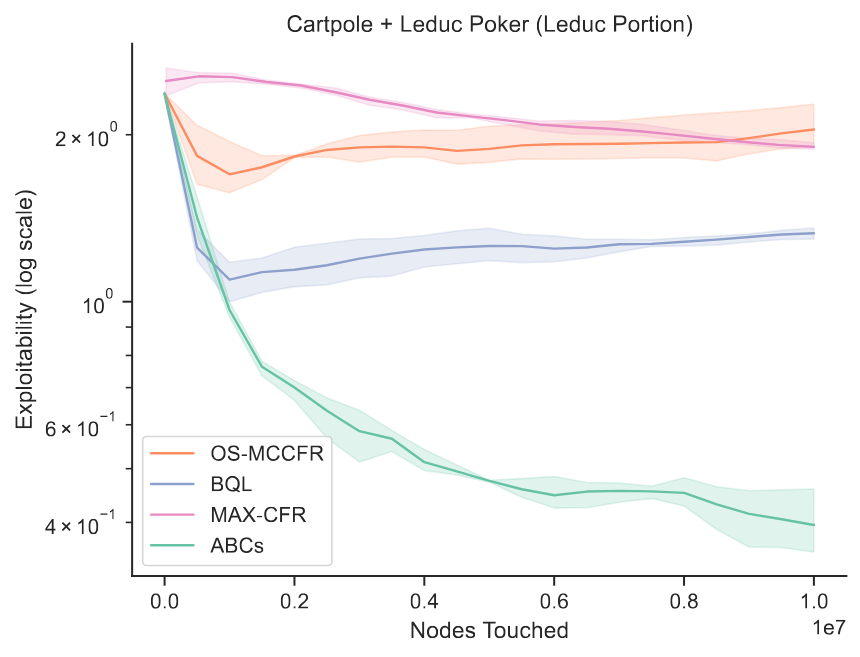
Luca D'Amico-Wong* , Hugh Zhang*, Marc Lanctot , David C. Parkes code Unified algorithm for both reinforcement learning and game theory. Can solve MDPs as fast as RL methods and imperfect-information games as fast as CFR using the single set of hyperparameters. |

|
Anton Bakhtin*, Noam Brown*, Emily Dinan*, Gabriele Farina*, Colin Flaherty*, Daniel Fried*, Andrew Goff*, Jonathan Gray*, Hengyuan Hu*, Athul Paul Jacob*, Mojtaba Komeili*, Karthik Konath*, Adam Lerer*, Mike Lewis*, Alexander H. Miller*, Sasha Mitts*, Adithya Renduchintala*, Stephen Roller*, Dirk Rowe*, Weiyan Shi*, Joe Spisak*, Alexander Wei*, David Wu*, Hugh Zhang*, Markus Zijlstra* Science, 2022 paper / blog / nyt / economist / gizmodo / forbes / new scientist / ars technica / mit tech review / kotaku / engadget / register / hacker news / reddit Human level performance in the game of Diplomacy, where agents negotiate with other humans in natural language. |
|
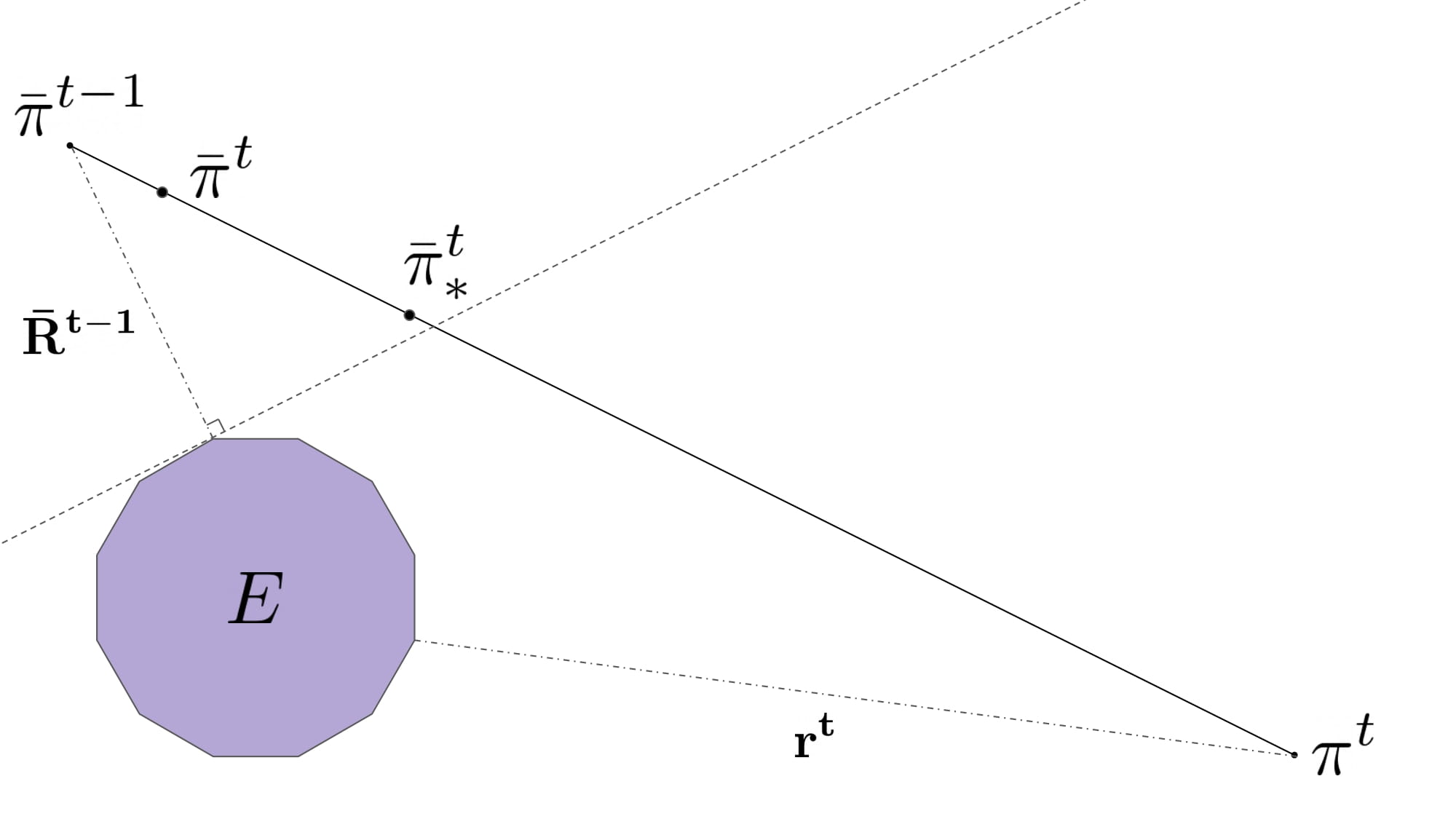
Hugh Zhang, Adam Lerer, Noam Brown Association for the Advancement of Artificial Intelligence (AAAI), 2022 A novel no-regret learning procedure that converges to correlated and coarse-correlated equilibria several orders of magnitude faster than previous methods in randomly generated normal-form games. |
|
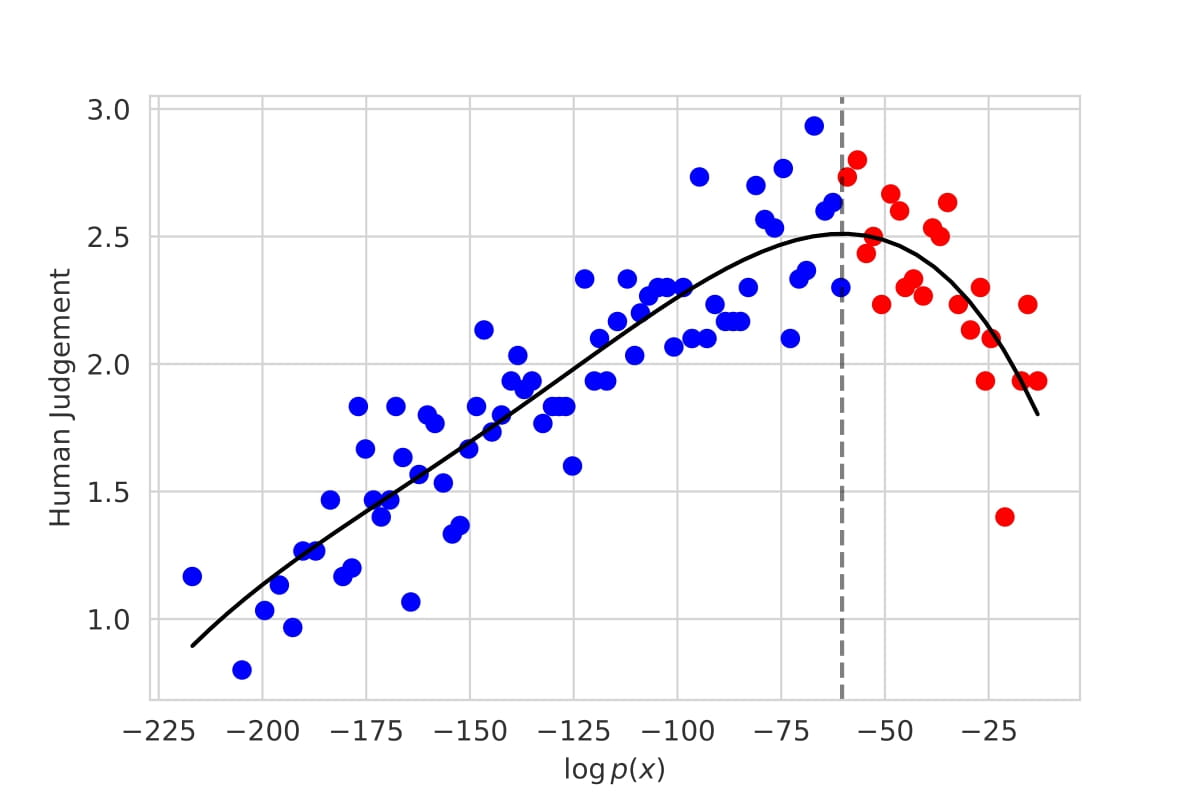
Hugh Zhang*, Daniel Duckworth*, Daphne Ippolito, Arvind Neelakantan Workshop on Human Evaluation of Natural Language Processing Systems at the Conference of the European Chapter of the Association for Computational Linguistics (HumEval Workshop @EACL), 2021 The first large-scale evaluation of decoding methods for large language models along the entire quality-diversity spectrum. |
|
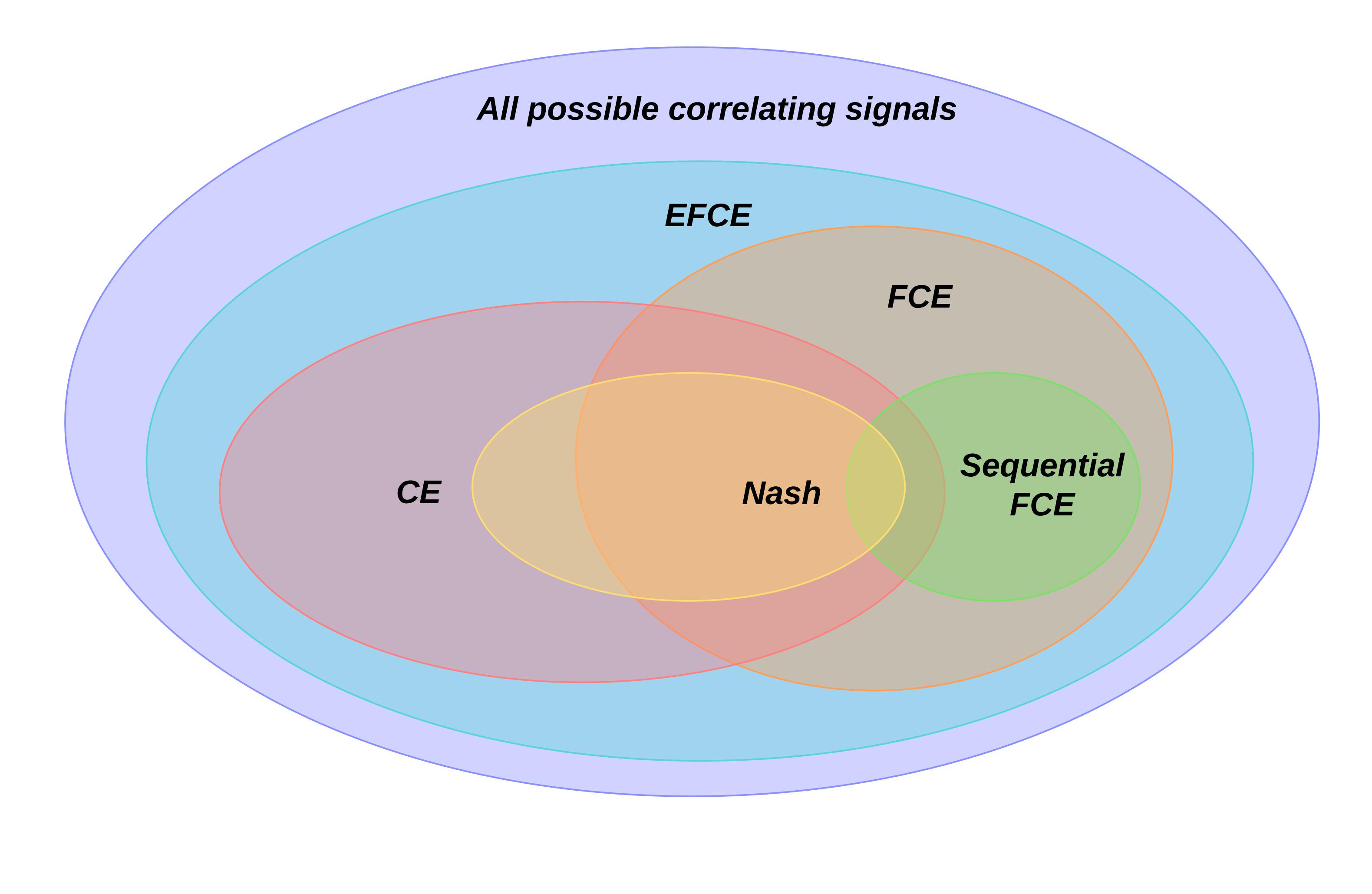
Hugh Zhang (advised by Gabriel Carroll) Stanford Senior Honors Thesis in Economics, 2020 (John G. Sobieski Award for Creative Thinking) Alongside Celli et. al (2020) (concurrent work), this paper gives the first internal regret minimization dynamics for extensive-form games. |
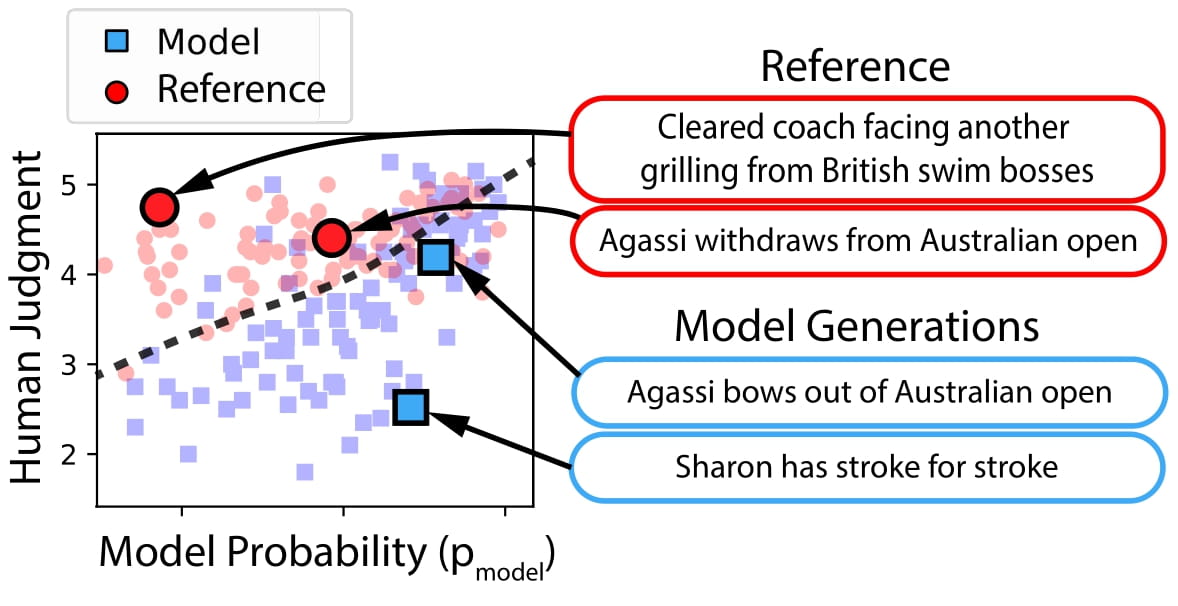
|
Tatsunori Hashimoto* , Hugh Zhang*, Percy Liang North American Chapter of the Association for Computational Linguistics (NAACL), 2019 (Oral Presentation) Existing language models can generate either high quality or diverse utterances, but not both simultaneously. How can we measure that in a single metric? |